
보통 여자가 남자보다 오래 산다고 한다. 통계청 자료(2005년 기준)에 따르면 남자는 75.14년, 여자는 81.89년. 무려 6.75년이나 차이 난다. 그럼 우리나라만 이렇게 남녀간의 기대수명에 차이가 나는 걸까? 통계청 자료에 보니 OECD 가입국 자료가 있던데 2003년 자료가 그나마 빈 셀 없이 꽉~ 찼기에 이 자료를 기준으로 확인해 보자.
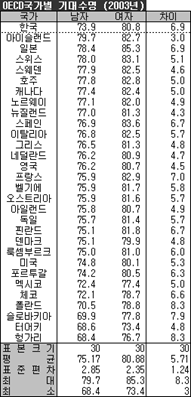
평균적으로 남녀간 5.71세의 기대수명 차이가 있는데 과연 이것을 보고 차이가 있다고 말할 수 있을까? 어떤 이는 10세보다 작으므로 차이가 없다고 할 수도 있을 것이요, 또 어떤 이는 2세보다 크므로 차이가 있다고 할 수도 있을 것이다. 그래서 이럴 때 통계적 방법을 이용하면 객관적으로 말할 수 있게 된다.
우선 차이를 확인한다는 것은 가설을 검정한다는 것이다. 그래서 검정을 위해 가설을 먼저 세워야 한다.
일차적으로 대립가설(H1)을 먼저 세운다. 대립가설은 기본적으로 새롭게 주장하고 싶은 것이 된다. 또는 평등하지 않다는 것이 된다(이는 귀무가설 H0이 평등하다는 전제를 안고 있어서다. 그래서 '귀무 歸無'이다).
그랬을 때 대립가설은 '남녀간 기대수명에 차이가 있다' 정도로 하면 되겠다.
또는 여자가 남자 보다 기대수명이 더 길다" 정도.
그리고 귀무가설(H0)은 대립가설의 반대다. 즉 귀무가설과 대립가설은 서로 공존할 수 없는 배반사건이다.
여기서 첫 번째 대립가설 '차이가 있다'는 것은 음이든 양이든 어느 쪽에서도 차이는 발생할 수 있다. 즉 음양 양쪽 모두를 재봐야 된다는 얘기. 그래서 통계는 이를 양측검정이라 한다. 그리고 두 번째 대립가설 '더 길다'는 것은 어느 한쪽만 확인하면 된다는 얘기다. 그래서 이를 단측검정이라 한다.
그리고 고려할 것이 또 있다. 두 집단, 여기서는 남자, 여자 변수의 분산이 같은 지 다른 지부터 알아야 한다. 두 집단간 분산 검정은 다음에 기회 있을 때 살펴보는 것으로 미루지만, 실질적으로 등(等)분산인지 이(異)분산인지 고민할 것 없이 그냥 모두 계산해 버리면 된다.
이 때 이분산이라면 중심극한정리에서 표본크기가 30 이상이면 표본평균은 정규분포에 근사한다고 했으니 표본크기가 큰 경우는 정규분포를 적용한다. 그리고 등분산이라면 T-분포를 이용한다. 물론 이 때도 표본크기가 크면 그냥 정규분포를 쓴다. 이외에 분산을 이미 알고 있냐 모르고 있냐에 따라서도 구분해 적용해야 되지만 이 또한 표본크기가 크다면 그냥 정규분포를 쓰면 된다. 중심극한정리는 이렇 듯 강력하다.
여차저차해서 단측/양측, 등분산/이분산이라는 구분을 가지고 검정통계량과 기각역 및 유의확률을 구해보면,
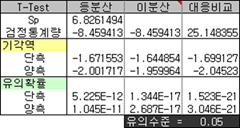
그러고 보니 대응비교를 빠뜨렸군. 대응비교는 처음 표에서 '차이'를 말한다. 즉 동일한 조사대상으로부터 얻은 두 변수(남녀) 간 차이를 구해 이를 검정하는 것이다. 그리고 기각역은 검정통계량이 차이가 있는지 없는지를 판단하는 기준으로 양측검정에서는 검정통계량의 절대값이 기각역보다 크면 귀무가설을 기각한다.
수식을 같이 사용하다 보니 양측 기각역도 음수인데 그냥 절대값을 이용하면 된다.
단측검정에서는 검정통계량이 양 또는 음의 어느 한쪽 방향으로 봤을 때 기각역보다 크다거나 또는 작다면 귀무가설을 기각한다.
그런데 두 집단간 차이가 있으려면 어떠해야 할까? 아마도 두 집단이 서로 멀리 떨어져 있으면 차이가 있다고 말하기 쉬울 것이다. 그리고 분산이 작으면 두 집단은 상대적으로 서로 떨어져 보이므로 이 또한 차이가 있다고 말하기 수월해진다.
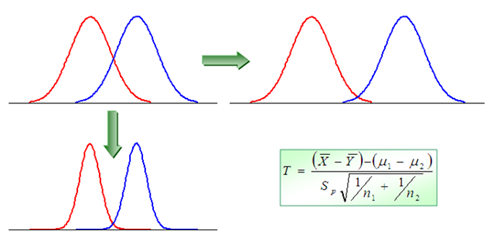
이런 상황을 종합적으로 나타내는 수치가 검정통계량이다. 검정통계량은 평균 차이에 비례하고 분산에 반비례하게 구성된다. 이렇게 통계는 계산이 조금 남다를 뿐이지 기본 줄거리는 일반 상식과 크게 다르지 않다. 여기서 기각역은 유의수준에 종속되므로 다른 유의수준, 예를 들어 0.01을 사용하려면 또 계산을 해야 되는 불편함이 있다.
그래서 유의확률 P-value를 이용하면 편리하다. 그리고 유의확률이 유의수준보다 작으면 귀무가설을 기각한다. 즉 귀무가설이 맞다고 가정할 때 해당 검정통계량이 나타날 확률로, 유의확률이 작다면 귀무가설에서 벗어날 가능성이 높아지기 때문이다.
그런데 엑셀로 하려니 암만 생각해도 복잡하다. Normsdist, Normsinv, Tdist, Tinv 등 듣도보도 못한 통계 함수를 새롭게 알아야 하니 말이다. 다행히 좀 더 간단한 함수가 있는데 Ttest라는 것이다. 위의 검정 과정을 T-검정이라고 하는데서 따온 함수로 이것은 단측/양측, 등분산/이분산/대응비교를 구분지어 유의확률을 계산해 준다.
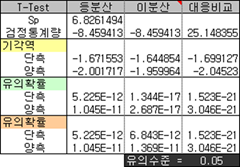
아래 유의확률이 Ttest 함수의 결과인데, 이분산인 경우 앞에서 구한 유의확률과 서로 다르다. 이는 정규분포에 근사한다는 가정을 적용했느냐 아니냐의 문제인데 큰 문제가 될 것 같지는 않다. 유의확률이 10에 -12, -17승으로 이건 그냥 0이다(물론 진짜 0은 아니지만 그냥 이건 0이라고 우긴다. 좀 있어 보이게 말한다면 0에 근사한다 정도).
참고로 표본크기가 작고 이분산인 경우에 대해서는 개론 수준에서는 다루고 있지 않다. 개론에서 다루고 있지 않다는 것은 역으로 일반적으로 통용할 수 있는 방법이 딱히 없기에 개별적으로 접근해야 되는데, 이 때 아무거나 가져와 사용하기에는 위험성이 높을 수 있다는 얘기가 되겠다.
어쨌거나 Ttest 함수를 통해 유의확률을 얻었고 이는 유의수준 0.05 보다 작으므로 단측이든 양측이든 귀무가설을 기각하게 된다. 물론 유의수준 0.01에서도 귀무가설을 강하게 기각한다. 즉 남녀간 기대수명에는 차이가 있을뿐만 아니라 남자보다 여자가 더 오래 산다는 것이다. 다른 나라들도 마찬가지다.
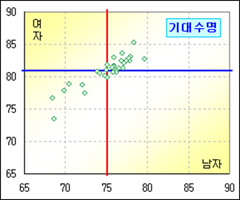
그런데 왜 차이가 생기는 거지? 위의 검정 과정은 기본적으로 남과 여는 서로 독립이라는 가정에 기반을 두고 있다. 이는 곧 기대수명은 서로 같다는 귀무가설을 은근히(?) 지지하고 있다. 그런데 위에서처럼 귀무가설이 기각됐다면 적어도 독립이 아닐 가능성이 높다는 것이다. 이는 앞서 XY 산점도에서 보듯이 두 변수간의 상관계수가 0.9033으로 매우 높게 나오는 것으로도 유추할 수 있다. 서로 독립이라는 가정에 충실했다면 상관계수는 0에 가까왔을 것이다.
여기서 잠깐! 상관계수는 두 변수간의 상관성을 설명해 주는 수치가 아니다. 단지 제한적 범위에서 상관성을 설명해 주는 수치일 뿐이다.
왠 궤변?
상관관계를 상관계수가 아니라면 뭘로 기술하려고?(쓰고 보니 내가 다 어리둥절하다) 만약에 산점도가 직선(1차함수)이 아니라 곡선(2차함수)으로 나왔다면 상관계수는 0에 가까와진다. 그러나 상관계수가 0이라고 두 변수 간의 상관성을 부정할 수는 없다. 그러므로 상관계수는 직관적이기는 하나 맹목적으로 추종해서는 안 된다.
그럼 다시... 그런데 왜 남녀간 기대수명에 차이가 생기는 거지? 남녀간 평등하지 않기 때문이라고 가설검정 결과는 얘기하고 있는데, 그렇다면 그 차이의 근원은 무엇일까?
크게 생리적 차이, 환경적 차이로 봤을 때, 남녀는 나온데 들어간데가 태생적으로 다르니 생리적 차이를 제외하긴 어렵겠다. 그리고 다른 하나는 환경적 차이인데, 이를 공간으로 제한해 접근한다면 그리 큰 설득력이 없겠다. 왜냐하면 위의 자료가 지리적 위치가 서로 다른 국가별 자료인데 그 차이의 분포가 골고루 분산되어 나타나기 때문이다. 그렇다면 생리적 차이가 좀 더 심증이 간다. 그런데 일전에도 얘기했듯이 통계는 상관관계를 다루지 인과관계를 다루지 않으므로 이는 해당 과학이 밝혀야 될 숙제 되겠다.
만약에 차이의 근원을 밝힌다면, 차이를 줄일 수도 있고 더 나아가 생명을 연장할 수도 있겠다. 노벨 의학상은 따논 당상 아닐까?