
동일 업종 내에서 몇몇 점포를 추출해 주당 판매량과 매출액을 조사하여 아래와 같은 자료를 얻었다고 하자
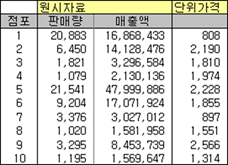
단위가격 정보를 봐서는 1, 7번 점포는 박리다매형인지 아주 싸게 판다(또는 저렴한 제품만을 다룬다). 그리고 9번 점포는 정가로만 팔거나 아니면 고가의 제품을 주로 다룬다고 유추할 수 있겠다. 어쨌거나 위의 자료를 가지고 판매량과 매출액 간의 관계를 단순회귀모형으로 예상하여 결정계수(R²)를 구해 보자.
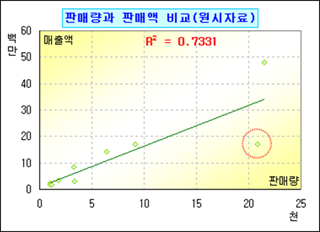
결정계수가 0.7331이기에 판매량으로 매출액을 추정하는 것은 어느 정도 설명력을 갖고 있어 보인다. 참고로 회귀모형이 유의미한 지는 별도 검정 단계를 거쳐야 하는데 여기서는 건너 뛴다.
그런데 암만 봐도 저 붉은 동그라미 안의 수치가 영 눈에 거슬린다. 이렇게 유독 동떨어진 자료를 이상치라 한다. 이상치에 해당하는 점포의 판매 자료를 제외하고 다시 결정계수를 구하면,
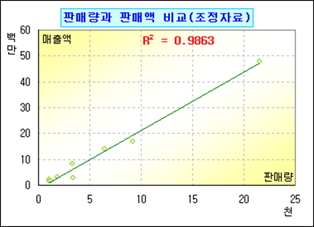
단지 자료 하나 제외한 것 뿐인데 결정계수가 0.9863으로 0.25 증가했다. 어느 정도의 희생으로 더 효과적인 결과를 얻게 된 것이다.
그렇다면 이때 이상치를 포함한 분석과 이상치를 제외한 분석 중 어느 분석 방식을 선택해야 하나?
물론 이상치를 어떻게 규정하고 선택할 것이냐는 중요하고 예민한 부분이다. 분석 방법에 따라 이상치를 구분하는 방식도 다양하다. 위의 자료는 표준화 잔차가 이상치 기각역을 초과하지 않으므로 실제적으로 이상치는 아니지만 여기선 이상치 기각역을 초과했다고 가정하겠다. 이론적으로는 원인을 파악하고 별다른 오류가 없다면 이상치를 제외하고 분석해야 한다고 하지만 이 선택은 분석자 몫이다.
그런데 매우 희귀한 자료이거나 자료가 적을 때에는 이상치라도 버리기 아쉬울 때가 있다. 이럴 땐 제외시키기 보다는 '보정'이라는 제3의 길을 선택할 수 있다.
보정? 조금 낯선 단어일 텐데, 좋게 말하면 수정이고 악의적으로 말하면 조작이다(이렇게까지 비약하면 돌 날아올 것 같긴 하다).
그렇다면 '보정'과 '조작'은 어떻게 구분할까?
분석자의 의도를 선과 악으로 구분하면 어떨까? 선의로 했으면 대충 넘어가고 악의로 했다면 매장시키는... 좀 썰렁했나. 그 기준은 객관성과 합리성에 있다. 남들도 두루 인정할 기준으로 이상치를 구분하고 보정해야 하는 것이다.
그런데 이 보다 더한 경우는 결측치가 발생될 때다. 이럴 땐 대세에 큰 영향을 주지 않는 범위 내에서 결측치를 추정/대체하여 분석을 진행하는 것이다. 자료가 많다면 일부러 대체할 필요는 없겠지만...
이와 비슷한 경우는 비일비재하고, 어떤 때에는 보정과 조작의 경계선에서 위태로운 줄타기를 하기도 한다. 이것이 현실이다!